УДК 621.317.08: 621.317.1: 621.317.6
СРАВНЕНИЕ ИДЕНТИФИКАЦИОННЫХ АЛГОРИТМОВ ДЕЦИМАЦИИ СИГНАЛОВ
А. А. Горшенков1, Ю. Н. Кликушин1, Б. В. Кошекова2
1Омский государственный технический университет, Россия
2Северо-Казахстанский государственный университет им. М. Козыбаева, Республика Казахстан
Получена 30 марта 2011 г., после доработки – 2 апреля 2011 г.
Аннотация. Описаны алгоритмы децимации (прореживания) сигналов, основанные на использовании средств и методов идентификационных измерений. Проведено моделирование предложенных алгоритмов и их сравнительный анализ с точки зрения эффективности преобразования.
Ключевые слова: алгоритм, децимация, идентификационный метод, параметр сжатия, погрешность адекватности, эффективность преобразования, цифровая обработка сигналов.
Abstract. Signal decimation algorithms, based on the use of means and methods of identification measurements, are described. The simulation of the proposed algorithms and their comparative analysis in terms of conversion efficiency are carried out.
Keywords: algorithm, decimation identification method, the compression setting, the error of the adequacy, efficiency of conversion, digital signal processing.
ВВЕДЕНИЕ
При цифровой обработке сигналов (ЦОС) очень часто возникает задача сжатия сигналов, с целью, например, их архивации. Познавательной основой для проведения операций сжатия служит гипотеза об информационной избыточности анализируемого сигнала. Наиболее просто, в отношении сигналов, данная задача решается с помощью алгоритма децимации, физический смысл которого состоит в исключении неинформативных отсчетов исходной выборочной реализации [1].
В современных программных системах ЦОС и анализа данных, например, LabVIEW, имеются соответствующие инструменты (например, Decimate 1D Array.vi) для реализации указанной функции. Однако, для корректного практического использования этих инструментов, требуются дополнительные (априорные) знания о форме входного сигнала, поскольку от этого напрямую зависит эффективность преобразования. При этом, пользователь должен знать заранее, какое значение фактора сжатия можно задать, а какое – нет, с тем, чтобы сигнал можно было восстановить, например, линейным полиномом, с заданной погрешностью [2]. Поэтому, в большинстве случаев, алгоритмы децимации реализуются не в автоматическом, а в интерактивном режиме, который подразумевает непосредственное участие пользователя. При этом приходится использовать тактику последовательных приближений, добиваясь достижения максимальной компрессии с учетом уровня допустимых искажений, которые, в свою очередь контролируются лишь визуально. Таким образом, из чисто технической, процедура децимации превращается в творческий, интеллектуальный процесс, результаты которого во многом зависят от опыта и интуиции пользователя.
Целью данной работы является доказательство возможности автоматизации процесса децимации и повышение, на этой основе, объективности и достоверности результатов преобразования. Ожидаемым эффектом применения предлагаемых алгоритмов является достижение оптимального сочетания параметров децимации (в координатах фактор сжатия – погрешность преобразования) вне зависимости от формы исходного сигнала.
Возможность непосредственного учета информации о форме входного сигнала в числовом виде, по мнению авторов, заложена в теории идентификационных измерений, поскольку содержанием этой теории является измерение формы и вариабельности сигналов [3].
Описанные в данной работе инструменты и технологии идентификационной децимации могут быть использованы для построения аппаратно-программных средств ЦОС.
МЕТОДИКА И ИНСТРУМЕНТЫ ИССЛЕДОВАНИЯ
Методика исследований
основана на компьютерном моделировании структурной схемы (рис. 1). Структурная схема модели идентификационного дециматора содержит два идентификационных
тестера (IdP-тестер), устройство сравнения и дециматор. В качестве последнего элемента используется стандартный,
библиотечный инструмент
(Decimate 1D Array.vi), удаляющий из исходной выборки
четные (нечетные) отсчеты. Левый по схеме идентификационный тестер (IdP-тестер) измеряет форму распределения входного
сигнала, представленного в виде массива X(t). Правый IdP-тестер измеряет форму распределения
выходного сигнала Y(t). Символом IdP[..] обозначена операция отображения тестером массива
сигнала в особое, идентификационное число. Идентификационные числа Sx, Sy на выходах соответствующих тестеров сравниваются
компаратором, выходной сигнал которого управляет работой дециматора. Максимально допустимое значение
погрешности сравнения (Delta-доп)
задается пользователем заранее. Дециматор
удаляет из выборки
четные (нечетные) отсчеты до тех пор, пока текущая разность (Delta S) между
показаниями идентификационных тестеров не превысит допустимого значения Delta(доп) погрешности преобразования.
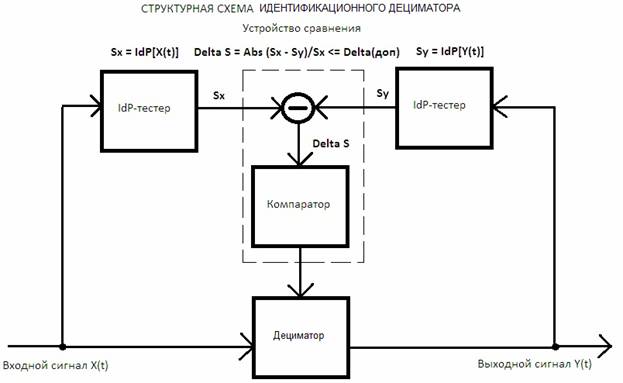
Рис. 1. Структурная схема модели идентификационного дециматора.
Таким образом, предлагаемое устройство представляет собой систему автоматического регулирования степени прореживания в зависимости от формы входного сигнала. Достоинством подобного решения является то, что пользователю легче и удобнее задать значение допустимой погрешности сравнения. Это гарантирует ему адаптивность обработки сигналов произвольной формы и не надо гадать, можно ли для данного сигнала установить требуемый фактор сжатия.
Информативными параметрами идентификационного дециматора являются: выборочная реализация выходного сигнала Y(t); фактор сжатия (Decimate Factor) и погрешность адекватности (Delta S = δ). Фактор сжатия показывает, во сколько раз объем выборки исходного сигнала X(t) больше объема выборки выходного сигнала Y(t). Погрешность адекватности (δ) показывает на сколько (в относительных единицах или %) форма сигнала на выходе отличается от формы сигнала на входе при наступлении условия идентификационной эквивалентности: Sx = Sy [1± δ].
Для сравнения с другими, подобными устройствами предлагается также использовать интегральный, комплексный показатель эффективности µ, равный отношению фактора сжатия (C) и погрешности (δ) адекватности. В соответствие с этим показателем, тот алгоритм прореживания лучше, у которого показатель эффективности больше. В свою очередь, эффективность больше тогда, когда фактор сжатия больше, а погрешность адекватности – меньше.
Основными блоками управляющей части структурной схемы (рис. 1) являются идентификационные тестеры, осуществляющие преобразование типа «массив на входе – число на выходе». Чтобы тестеры измеряли именно форму распределения, а не какое-то другое, свойство сигнала, необходимо оговорить условия, которым должны удовлетворять идентификационные числа. К условиям, ограничивающим область существования идентификационных тестеров, относятся следующие.
1. Масштабная инвариантность:
![]() ,
(1)
,
(1)
где Id[..] – условное обозначение операции идентификации, реализуемой с помощью тестера, А, В, C – постоянные коэффициенты. В соответствие с (1) идентификационное число (G) не зависит от линейных преобразований исходного множества. В отношении масштабной инвариантности идентификационные числа подобны фрактальным числам, которые, как известно [4], характеризуют фрактальную размерность (размерность Хаусдорфа – Безиковича) объектов или процессов. С помощью фрактальной размерности интегрально оценивается структурная сложность объектов или процессов.
2. Эквивалентность, в соответствие с которой
«Если G1 = Id[F1(t)], G2 = Id[F2(t)], то при G1 = G2, имеем F1(t) ≡ F2(t)», (2)
где знак «≡» означает, что эти сигналы эквивалентны в идентификационном, но не в строгом математическом смысле. Аналогом данного принципа в измерительной технике является компарирование сигналов переменного тока сигналами постоянного тока, реализуемое, например, на базе электротепловых преобразователей [5]. Примером применения данного принципа в области статистических измерений является замена неизвестного распределения погрешностей средства измерения эквивалентным (в информационном смысле) ему равномерным распределением. На базе этого предложения выстроена, так называемая, информационная теория измерений [6]. В общем случае можно говорить о том, что принцип идентификационной эквивалентности является обобщением понятия равенства F1(t) = F2(t) сигналов.
3. Согласованная упорядоченность, при которой
«Если G1 > G2 > …>Gn , то S1 > S2 > …>Sn или S1 < S2 < …<Sn ». (3)
Данное свойство означает, что упорядоченности G1 > G2 > …>Gn идентификационных чисел должна соответствовать та или иная упорядоченность (S1 > S2 > …>Sn или S1 < S2 < …<Sn) интенсивности проявления свойства S объекта или процесса. Отдаленным и частичным аналогом условия (3) является свойство монотонности функций.
Указанные условия выполняются, в частности, для идентификационного тестера NF-типа, использованного в данных исследованиях. Математическая модель (4) данного тестера связана с вычислением отношения размаха сигнала к его среднеквадратическому отклонению (СКО) и трактует обработку значений {X} сигнала как преобразование количества информации объема N на входе, в количество информации объема NF на выходе [7].
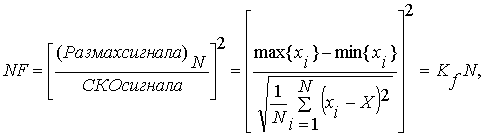 (4)
(4)
Идентификационный параметр NF будем называть виртуальным объемом.
Известным ближайшим аналогом данного параметра является коэффициент амплитуды, используемый в технике преобразования сигналов для оценки уровня нелинейных искажений радиотехнических и электронных устройств [8]. Структура программного кода NF-тестера представлена на рис. 2, а в таблице 1 дана его статическая (рекогнитивная или распознавательная) характеристика для случайных сигналов с двумодальным (2mod), арксинусным (asin), равномерным (even), треугольным (simp), нормальным (gaus), двусторонним экспоненциальным (lapl) и Коши (kosh) распределениями, полученные для объема выборки N=10000 и числе реализаций L=100. Здесь же указаны имена некоторых периодических (squ – прямоугольный типа меандр, sin – синусоидальный, tri – треугольный, saw – пилообразный) сигналов, имеющих соответствующие случайным сигналам распределения.
Рис. 2. Структура программного кода NF-тестера.
Таблица 1. Распознавательная характеристика NF-тестера.
|
IdP=NF |
Вид распределения случайного сигнала |
||||||
|
2mod |
asin |
even |
simp |
gaus |
lapl |
kosh |
|
|
Ранг (порядковый номер) |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
Mean (NF), N=10000,L=100 |
4 |
8 |
12 |
24 |
60 |
150 |
N..2N |
|
Периодические аналоги |
Squ |
Sin, Cos |
Tri, Saw |
|
|
|
|
Распознавательная характеристика иллюстрирует объективно существующую, фундаментальную закономерность (согласованную упорядоченность) связи, как между формами распределений случайных, так и между формами периодических сигналов.
В табличной форме эта связь носит название идентификационной шкалы (ИШ), которая устанавливает соответствие между количественными (значение идентификационного числа, например, NF = 60) и качественными (имя, например, gaus, распределения мгновенных значений) показателями. Это позволяет использовать идентификационные тестеры для решения задач автоматического распознавания и классификации сигналов.
В контексте данной работы используются только количественные показатели NF-тестера в виде его идентификационного числа.
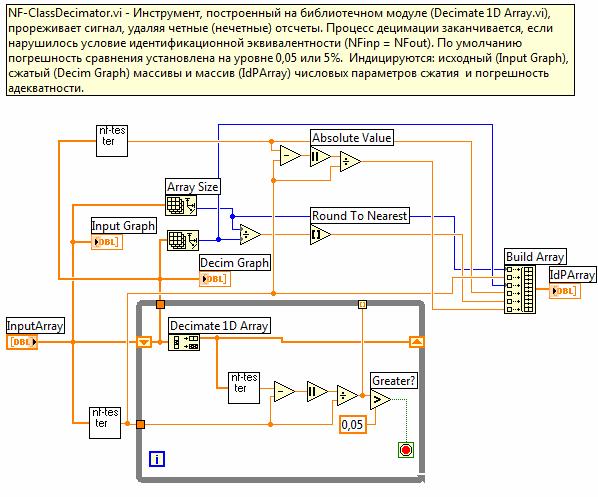
Рис. 3. Структура программного кода идентификационного дециматора.
Алгоритм работы идентификационного дециматора
представлен в виде программного кода (рис. 3) виртуального прибора (ВП),
выполненного в среде LabVIEW.
Основу ВП составляют два идентификационных тестера NF-типа и дециматор, построенный на библиотечном модуле Decimate 1D Array.vi.
Компаратор, осуществляющий сравнение идентификационных чисел входного и децимируемого
сигналов, построен на элементах вычитания и сравнения. С помощью переменной
цикла While-Loop формируется число, задающее текущее значение (i) степени децимации так, что фактор
сжатия определяется через это число, как 2i. Следовательно, при i=0 фактор сжатия равен 1 (компрессия отсутствует), а при ![]() - компрессия
максимальна и объем выборки выходного сигнала равен 1. Количественные параметры
работы устройства: объем выборки (N) входного сигнала, идентификационное число (NFin) входного сигнала, объем выборки (Nout) выходного сигнала,
идентификационное число (NFout)
выходного сигнала, фактор сжатия и погрешность адекватности (δ) выводятся
в виде массива IdP Array.
- компрессия
максимальна и объем выборки выходного сигнала равен 1. Количественные параметры
работы устройства: объем выборки (N) входного сигнала, идентификационное число (NFin) входного сигнала, объем выборки (Nout) выходного сигнала,
идентификационное число (NFout)
выходного сигнала, фактор сжатия и погрешность адекватности (δ) выводятся
в виде массива IdP Array.
На рис. 4 представлены данные анализа тестовых синусоидального и косинусоидального сигналов с помощью предлагаемого идентификационного метода. Полученные результаты, во-первых, подтверждают, выдвинутое ранее, предположение о зависимости фактора сжатия (пятое окно массива IdPArray) от формы (C[sin] = 32, C[cos] =67) сигнала. Во-вторых, погрешность адекватности (шестое окно массива IdPArray), хотя и не превышает допустимого значения в 5% (0,05), но зависит от формы сигнала (δ[sin] ≈ 4,3%, δ[cos] ≈ 3,3%) сложным образом. В частности, вместо ожидаемой корреляции вида «больше C – больше δ», в данном случае имеем соотношение «больше C – меньше δ» для косинусоидального сигнала. В-третьих, наблюдается явная связь результатов компрессии с начальной фазой сигналов. Это, в сою очередь, свидетельствует о наличии частотной зависимости фактора сжатия.
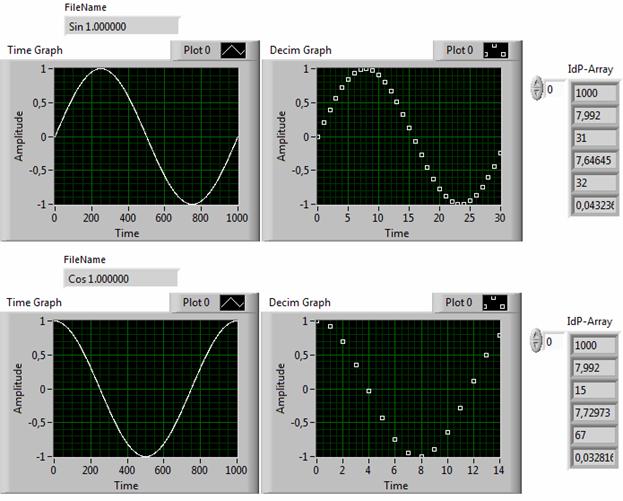
Рис. 4. Тестовый пример результатов работы идентификационного алгоритма прореживания.
Представленную на рис. 3 структуру можно усовершенствовать введением еще одного канала измерения формы прореживаемого сигнала.
Идея состоит в том, что, измеряя форму распределения и четных, и нечетных отсчетов, можно на следующий этап прореживания направлять ту часть, которая имеет меньшую погрешность адекватности. Таким образом, можно попытаться увеличить число циклов децимации. Данная идея реализована в структуре (рис. 5) программного кода модифицированного идентификационного дециматора. Все усовершенствования идентификационного дециматора сосредоточены в цикле While-Loop.
Дополнительный канал измерения распределения четных отсчетов содержит идентификационный тестер, схему вычисления погрешности адекватности, схему сравнения погрешностей двух каналов и коммутатор (Select). Добавлен также компаратор сравнения форм входного сигнала и формы сигнала дополнительного канала. Остановка процесса прореживания наступает, когда погрешности обоих каналов, совместно, превысят некоторое, наперед заданное, допустимое значение, например, 0,05.
Изучение особенностей обоих алгоритмов идентификационного прореживания проводилось по следующей программе. Во-первых, исследовалась возможность компрессии сигналов разных типов (периодические, случайные, фрактальные, модулированные, аддитивные смеси) и разной формы. Во-вторых, изучались свойства алгоритмов при варьировании значения допустимой погрешности сравнения. В-третьих, оценивались частотные характеристики алгоритмов для периодических сигналов.
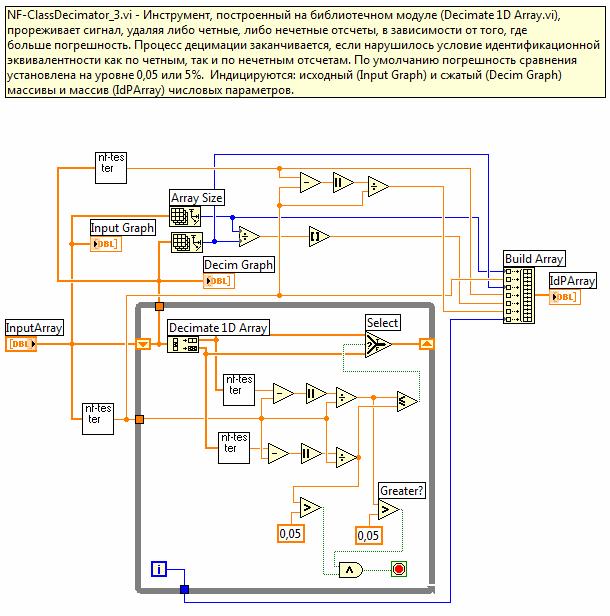
Рис. 5. Структура программного кода модифицированного идентификационного дециматора.
Правильность работы идентификационных алгоритмов оценивалась визуально путем сравнения временных, вероятностных и спектральных функций входного и выходного сигналов. Достоверность результатов дискретизации оценивалась количественно измерениями погрешности адекватности.
РЕЗУЛЬТАТЫ ИССЛЕДОВАНИЯ
Некоторые особенности обработки простых и сложных сигналов с помощью идентификационных алгоритмов децимации представлены на рис. 6-11.
Каждый рисунок состоит из 3-х дисплеев и 2-х цифровых окон. На левом верхнем дисплее отображается временная функция входного сигнала. На правом верхнем и левом нижнем дисплеях изображены временные функции, прореженные с помощью первого и второго идентификационных алгоритмов.
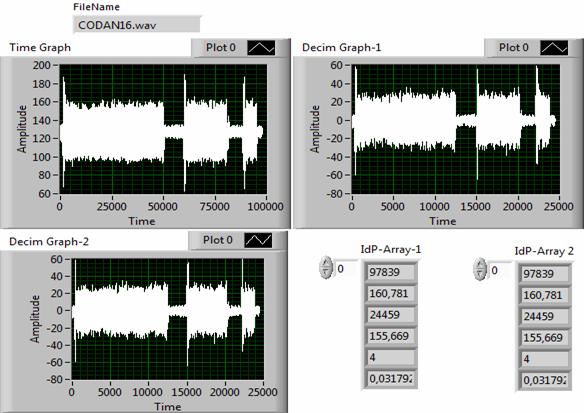
Рис. 6. Результаты анализа сигнала Cdn-16.
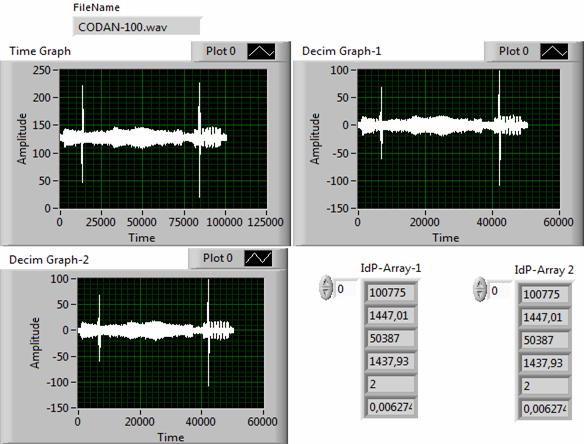
Рис. 7. Результаты анализа сигнала Cdn-100.
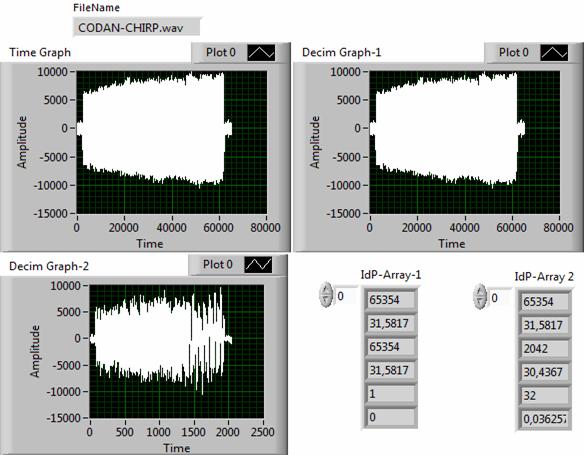
Рис. 8. Результаты анализа сигнала Cdn-Ch.
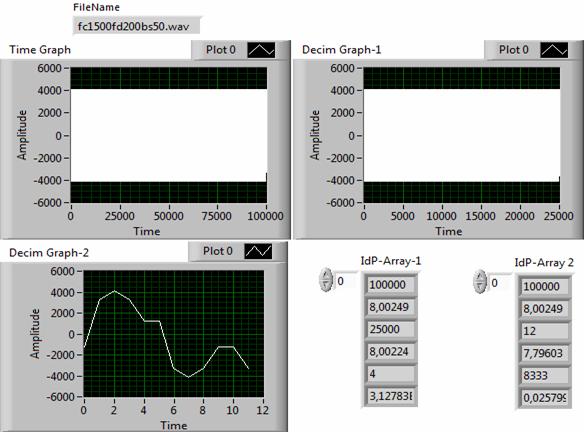
Рис. 9. Результаты анализа сигнала FC1500.
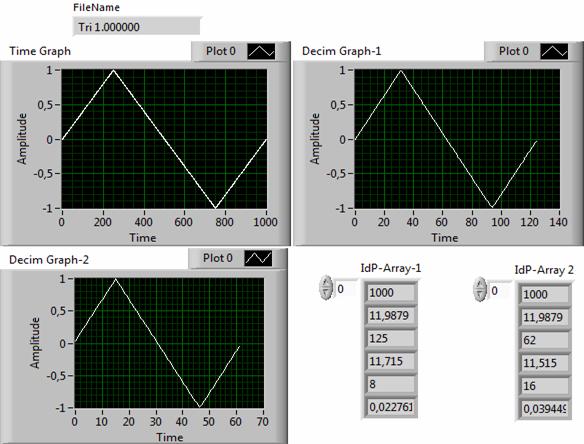
Рис. 10. Результаты анализа треугольного сигнала.
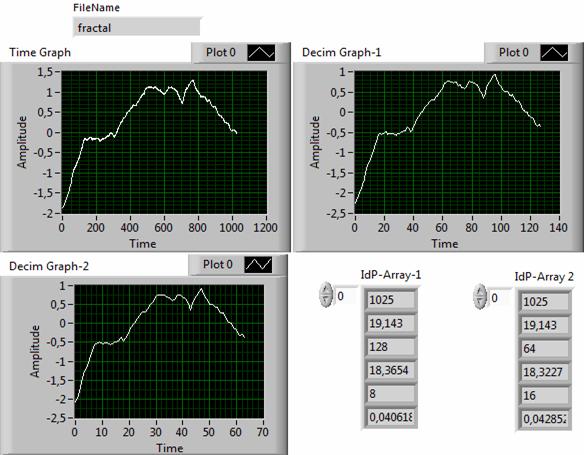
Рис. 11. Результаты анализа фрактального сигнала с
показателем Херста Н=1
В цифровых окнах IdPArray-1 и IdPArray-2 отображены результаты измерений следующих основных параметров: объем исходной выборки сигнала, идентификационное число исходного сигнала, объем выборки выходного сигнала, идентификационное число выходного сигнала, фактор сжатия и погрешность адекватности.
Сводные, по шести группам сигналов, результаты сравнительного анализа обоих алгоритмов представлены в табл. 2.
Таблица 2. Результаты сравнительного анализа сигналов
|
№п/п |
Имя сигнала |
Параметры 1-го алгоритма |
Параметры 2-го алгоритма |
Примечание |
||||
|
C |
δ |
µ |
C |
δ |
µ |
|||
|
1 |
Sin-1 |
32 |
0,043 |
744 |
32 |
0,04 |
800 |
Периодические сигналы единичной частоты |
|
2 |
Cos-1 |
67 |
0,033 |
2030 |
67 |
0,033 |
2030 |
|
|
3 |
Tri-1 |
8 |
0,023 |
348 |
16 |
0,04 |
400 |
|
|
4 |
Squ-1 |
32 |
0,03 |
1067 |
32 |
0,030 |
1067 |
|
|
5 |
Saw-1 |
8 |
0,021 |
381 |
8 |
0,021 |
381 |
|
|
6 |
Cdn-16 |
4 |
0,032 |
125 |
4 |
0,032 |
125 |
Сложно модулированные сигналы |
|
7 |
Cdn-100 |
2 |
0,0063 |
317 |
2 |
0,0063 |
317 |
|
|
8 |
Cdn-ch |
1 |
0 |
- |
32 |
0,036 |
889 |
|
|
9 |
Fc250 |
16 |
0,0003 |
53333 |
16 |
0,0003 |
53333 |
ЧМ сигналы |
|
10 |
Fc1000 |
8 |
0,00004 |
200000 |
8 |
0,00004 |
200000 |
|
|
11 |
Fc1500 |
4 |
0,00005 |
80000 |
8333 |
0,026 |
320500 |
|
|
12 |
Fr-1 |
15±13 |
0,03 |
500 |
18±14 |
0,03 |
600 |
Фрактальные сигналы |
|
13 |
Fr-0,5 |
5±4 |
0,02 |
250 |
8±6 |
0,03 |
267 |
|
|
14 |
Fr-0 |
1,3±0,65 |
0,008 |
163 |
2±2 |
0,015 |
133 |
|
|
15 |
ОСШ-0,2 |
1 |
0 |
- |
8 |
0,022 |
364 |
Аддитивные смеси типа сигнал-шум |
|
16 |
ОСШ-0,5 |
1 |
0 |
- |
2 |
0,017 |
118 |
|
|
17 |
ОСШ-1 |
1 |
0 |
- |
4 |
0,002 |
2000 |
|
|
18 |
ОСШ-2 |
2 |
0,013 |
154 |
2 |
0,013 |
154 |
|
|
19 |
ОСШ-5 |
1 |
0 |
- |
8 |
0,045 |
178 |
|
|
20 |
ОСШ-50 |
2 |
0,001 |
2000 |
64 |
0,038 |
1684 |
|
|
21 |
2mod |
44±30 |
0,024 |
1833 |
66±38 |
0,03 |
2200 |
Случайные стационарные сигналы (N=1000, L>=1000) |
|
22 |
Asin |
11±15 |
0,02 |
550 |
24±30 |
0,03 |
800 |
|
|
23 |
Even |
6,6±8 |
0,02 |
330 |
14±16 |
0,02 |
700 |
|
|
24 |
Simp |
2,5±2,5 |
0,02 |
125 |
6±5 |
0,03 |
200 |
|
|
25 |
Gaus |
1,5±1 |
0,014 |
100 |
2±2 |
0,02 |
100 |
|
|
26 |
Lapl |
1,2±0,5 |
0,005 |
240 |
1,5±1 |
0,01 |
150 |
|
|
27 |
kosh |
1±0,1 |
0,01 |
100 |
1±0,1 |
0,0005 |
2000 |
|
|
|
mean |
12,5 |
0,05 |
250 |
397 |
0,05 |
7940 |
|
ВЫВОДЫ
Анализ качественных и количественных результатов проведенных исследований показывает следующее.
Во-первых, оба рассмотренных идентификационных алгоритма позволяют автоматизировать процедуру компрессии сигналов, вне зависимости от их формы (свойство адаптивности). При этом следует выделить две группы сигналов. Одну группу образуют сигналы, которые сжимаются обоими алгоритмами одинаково. Во вторую группу входят сигналы, которые модифицированным алгоритмом сжимаются сильнее. Каков физический смысл подобной ситуации, предстоит выяснить при проведении дополнительных исследований.
Во-вторых, сжатые с помощью идентификационных алгоритмов сигналы не требуют последующего восстановления, поскольку выходная реализация сохраняет основные особенности исходной, в пределах той погрешности, которая удовлетворяет пользователя. Это обстоятельство особенно хорошо проиллюстрировано примером (рис. 11) анализа фрактального сигнала.
В-третьих, имеет смысл поставить вопрос о том, почему некоторые сигналы не сжимаются (C = 1) и можно ли в этом случае утверждать, что идентификационные алгоритмы являются инструментами измерения информационной избыточности.
В-четвертых, модифицированный алгоритм компрессии по совокупности рассмотренных сигналов оказался примерно в 32 раза эффективнее базового идентификационного алгоритма (строка mean, табл.2). Поэтому именно этот инструмент рекомендуется использовать для построения систем цифровой обработки сигналов.
ЛИТЕРАТУРА
1. Басараб М.А. Цифровая обработка сигналов на основе теоремы Уиттекера-Котельникова-Шеннона. – М.: Радиотехника, 2004. – 72 с.
2. Цыганенко В.Н., Белик А.Г. Дискретизация измерительных сигналов на основе прикладных функциональных моделей //Цифровая обработка сигналов. – М.: 2009. - №2. – С.58-60.
3. Кликушин Ю.Н. Идентификационные инструменты анализа и синтеза формы сигналов: Монография. – Омск: Изд-во ОмГТУ, 2010. – 216 с.
4. Федер Е. Фракталы. – М.: Мир, 1991.
5. Электрические измерения//Авт. Л.Ч. Чайка, Н.С. Добротворский, Б.М.Душин и др. – Л.: Энергия, 1980.
6. Новицкий П.В. Основы информационной теории измерительных устройств. – М.: Энергия, 1986.
7. Кликушин Ю.Н. Классификационные шкалы для распределений вероятности. [Электронный ресурс] // Журнал Радиоэлектроники [Электронный журнал], №11 (ноябрь), 2000 г. - М.: Институт радиотехники и электроники РАН, 2000 г. - Режим доступа: http://jre.cplire.ru/jre/nov00/4/text.html, свободный – Загл. с экрана.
8. Измерения в электронике // Справочник. Под ред. В.А.Кузнецова. - М.: Энергоатомиздат, 1987. - 511 с.