|
|
"ЖУРНАЛ РАДИОЭЛЕКТРОНИКИ" N 4, 2003 |
|
Метод
автоматизированного конструирования процедур обнаружения объектов по их
структурному описанию
* Буряк Д. Ю.,e-mail: buryakdm@mtu-net.ru
** Визильтер Ю. В.,e-mail: viz@gosniias.msk.ru
* МГУ им. М.В. Ломоносова, ** ФГУП ГосНИИ АС.
Полученa 02 апреля 2003 г.
Данная статья посвящена проблеме автоматизированного конструирования процедур анализа изображений. В работе приведено описание созданного метода автоматизированного построения процедур обнаружения объектов на изображении по их структурному описанию. В основе данного метода лежит идея формального преобразования исходной модели объекта. Для выполнения преобразований были введены операции над моделями. Конструирование процедуры поиска объекта на изображении основывается на его структурном описании и на моделях известных алгоритмов, которые находятся в базе знаний системы. В качестве известных алгоритмов были реализованы процедура классического преобразования Хафа и алгоритм рекурсивного перебора всех точек изображения для проверки условий из описания объекта. Метод был реализован в виде системы логического вывода.
1. Введение.
В настоящее время накоплен огромный опыт в решении задач распознавания изображений [1,2,3,4]. Предварительный анализ указанного опыта позволяет выделить ряд характерных особенностей, а именно:
· Наличие большого числа алгоритмов и подходов к решению различных задач. К сожалению, для подавляющего числа этих алгоритмов нельзя заранее предсказать, насколько оправдано (в смысле быстродействия, точности обнаружения и т.п.) их применение к конкретной проблеме.
· Практически для каждой задачи всегда можно подобрать несколько алгоритмов, решающих её, но выбор из них наиболее подходящего по некоторому набору критериев в большинстве случаев основывается на эвристических принципах и результатах экспериментов на конкретной задаче. Поэтому значительную долю времени разработчики тратят на реализацию подходящих алгоритмов и сравнение их между собой на результатах работы.
· В большинстве случаев для решения конкретных задач применяются различные комбинации уже известных алгоритмов, поскольку разработка совершенно нового алгоритма требует колоссального опыта работы в области компьютерного зрения.
Из анализа указанных особенностей следует, что одним из способов сокращения времени и затрат труда при разработке программного обеспечения для задач машинного зрения является применение средств, автоматизирующих процедуры выбора и настройки алгоритмов анализа изображений.
Исходя из вышесказанного, к одной из основных задач в области анализа изображений следует отнести разработку подходов к автоматизированному построению и выбору процедур распознавания, которые решают конкретную задачу и удовлетворяют некоторому набору критериев (быстродействия, точности распознавания и т.п.).
Актуальность сформированных выше положений может быть показана на примере решения типовой задачи обработки аэрофотоснимков.
Рассмотрим задачу выделения объектов на мелкомасштабных аэрофотоснимках (Рис. 1.) [5].

Рис. 1.

Рис. 2.
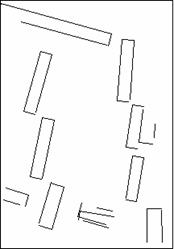
Рис. 3.
Необходимо обнаружить объекты, соответствующие контурам прямоугольных строений на снимке.
После предварительной обработки данного изображения, получим набор отрезков, которые образуют границы областей на исходном изображении (Рис. 2).
Искомый прямоугольный объект соответствует паре пересекающихся П-структур (Рис. 3). Рассмотрим два варианта алгоритма обнаружения П-структур на полученном изображении.
Вариант 1.
1. Найти все перекрывающиеся параллельные отрезки.
2. Для каждой пары параллельных отрезков найти отрезок, пересекающий их под прямым углом. Обнаруженная тройка отрезков будет образовывать П-структуру.
Вариант 2.
1. Найти пары перпендикулярных, перекрывающихся отрезков.
2. Для каждой обнаруженной пары найти отрезок, параллельный одному отрезку пары и перпендикулярный другому. В этом случае данная тройка будет образовывать П-структуру.
Рассмотренные варианты алгоритмов обнаружения отличаются как временем работы, так и количеством требуемой памяти. Однако априори нельзя сказать, какой из этих вариантов будет эффективнее, например, по критерию быстродействия. Пусть после предварительной обработки исходного изображения будет получено относительно небольшое число параллельных отрезков, тогда первый вариант алгоритма по критерию быстродействия будет более эффективным, чем второй, т.к. множество пар параллельных отрезков будет иметь небольшой размер. Напротив, если пар параллельных отрезков будет много, то второй вариант алгоритма может быть более быстрым.
Заметим, что предложенные варианты алгоритмов во многом тождественны и отличаются лишь порядком поиска составляющих элементов П-структуры.
Наличие автоматизированных процедур позволяет провести предварительный анализ и существенно сократить время и затраты труда при обработке изображений методами машинного зрения.
2. Подходы к построению процедур анализа изображений.
В настоящее время существует несколько подходов к построению и выбору процедур решения задач машинного зрения.
Один из подходов основывается на использовании библиотек процедур, реализующих различные алгоритмы обработки и анализа объектов на изображении. Часто вместе с библиотеками пользователю предоставляется графическая оболочка, обеспечивающая возможность опробовать предлагаемые процедуры на конкретных изображениях и спроектировать требуемую систему, используя приёмы визуального программирования. К программным системам, реализующим данный подход, относятся система Aphelion (www.adsic.net), группа средств eVision (www.euresys.com), система KBVision (www.aai.com/AAI), семейство систем Khoros (www.khoral.com), система NeatVision (www.neatvision.com).
К недостаткам систем, построенных на основе такого подхода, следует отнести техническую сложность автоматизированного построения процедур обнаружения заданного объекта, поэтому пользователь вынужден самостоятельно создавать и тестировать различные комбинации поддерживаемых системой алгоритмов.
Для решения данной проблемы были предложены несколько подходов.
Один из них основан на анализе задаваемого структурного описания объекта поиска. Далее, автоматически применяя к полученному описанию средства логического вывода, осуществляется построение алгоритма обнаружения. Такой подход реализует, например, система PIP [6,7]. Одним из её основных недостатков является однотипность получаемых алгоритмов - все они будут рекурсивные, т.к. исходная модель объекта не подвергается модификации.
Другой тип систем, автоматизирующих процесс конструирования процедур анализа изображений, базируется на теории генетического программирования [8]. Целевая программа автоматически конструируется из элементарных блоков, таких как арифметические операции, доступ к пикселям и т.п. Набор и порядок следования элементарных блоков определяется с помощью эволюционных алгоритмов, путём решения некоторой оптимизационной задачи. Отсюда следует один из главных недостатков подобных систем - они излишне формализовано подходят к решению, не используя опыт, накопленный в области анализа изображений. Примерами таких систем являются Discipulus и PADO [9].
3. Структура экспертной системы анализа изображений.
Данная работа выполнялась в рамках проекта по разработке специализированной экспертной системы для анализа цифровых изображений в задачах обнаружения и идентификации сложных структурных объектов на основе их структурно-вероятностного описания. Основное отличие данной системы от существующих заключается в том, что она позволяет получать как рекурсивные, так и нерекурсивные алгоритмы обнаружения объектов на изображении.
Создаваемая специализированная экспертная система (ЭС) состоит из следующих основных блоков:
1. Блок формального описания искомых объектов путём иерархического задания составляющих их элементов и отношений между этими элементами.
2. Блок преобразования описания (моделей) объектов.
3. Блок перевода декларативного описания объекта в соответствующее процедурное (т.е. сопоставление описанию объекта процедуры для его обнаружения на изображении).
4. Блок реализации полученных алгоритмов путём модификации типовых метаалгоритмов, соответствующих стандартным метамоделям.
5. Блок вероятностного описания элементов и моделей и расчёта характеристик достоверности их обнаружения.
6. Блок статистического анализа результатов обработки изображения.
7. Банк данных о программно-аппаратных характеристиках типовых процедур.
Разрабатываемая система предназначена для обнаружения контурных и полутоновых объектов на цветных и полутоновых изображениях.
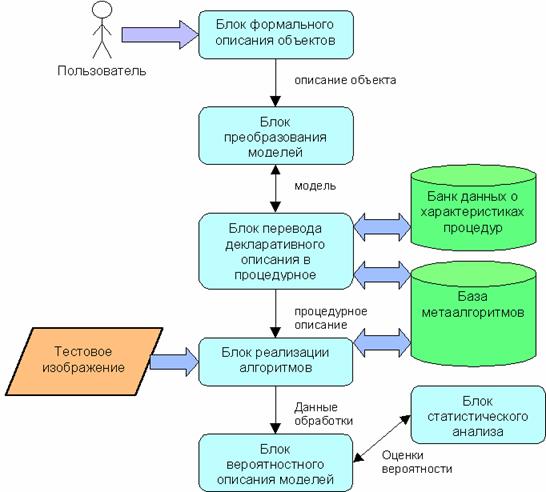
Рис.4.
Принцип работы данной системы заключается в следующем (рис. 4). Система получает от пользователя структурное описание объекта на «почти естественном» языке (блок 1). Данное описание определяет искомый объект как совокупность составляющих его элементов и связей между ними. Прототипом созданного языка задания спецификации искомого объекта является язык логического программирования Пролог [10]. Язык допускает рекурсивное определение искомого объекта. Блок 2 выполняет все допустимые формальные преобразования исходного описания, формируя дерево возможных решений. Блок 3 по моделям, расположенным в листовых вершинах этого дерева, осуществляет построение модульных процедур обнаружения заданного объекта. Таким образом осуществляется переход от структурного описания объекта к процедуре его поиска на изображении. Существует возможность проверить полученные решения на реальных изображениях (блок 4). Блок 5 позволяет на основе вероятностного описания моделей а также результатов выполнения составляющих элементов модульных процедур рассчитывать характеристики достоверности обнаружения и затем объяснять полученные выводы. Для назначения необходимых оценок вероятности используются как экспертные знания специалистов, так и блок статистического анализа результатов обработки изображения (блок 6). В систему также включён блок, содержащий сведения о быстродействии и других параметрах типовых алгоритмов при их реализации на различных вычислительных платформах; это позволяет производить отбор тех решений, которые не только соответствуют заданной модели, но и удовлетворяют ряду требований, предъявляемых к будущей системе обработки изображений.
Целью данной работы является создание метода автоматизированного конструирования процедур анализа изображений и его реализация в виде системы логического вывода, входящей в состав рассмотренной выше специализированной ЭС. Разрабатываемая система логического вывода реализует функции блоков 1, 2, 3 и 4 для низкоуровневых объектов, описание которых производится непосредственно на пиксельном уровне.
4. Метод автоматизированного конструирования процедур обнаружения.
Рассмотрим структурное описание некоторого контурного объекта Obj, который необходимо обнаружить на изображении:
![]()
Описание объекта представляет
собой параметрическую яркостно-геометрическую модель. Данную модель будем
интерпретировать как набор предикатов ![]() , соединённых между собой операциями конъюнкции.
Каждый предикат является некоторым условием, накладываемым на точки искомого
объекта и связи между ними. Заметим, что изображение на рассматриваемом этапе
не конкретизируется.
, соединённых между собой операциями конъюнкции.
Каждый предикат является некоторым условием, накладываемым на точки искомого
объекта и связи между ними. Заметим, что изображение на рассматриваемом этапе
не конкретизируется.
Задачей разрабатываемой системы логического вывода является построение набора процедур, позволяющих обнаруживать данный объект на изображении и реализующих алгоритмы заданных типов.
Для каждой построенной процедуры рассчитываются следующие оценки:
· количество операций;
· размер используемой памяти.
Построенные процедуры могут быть опробованы применительно к любому конкретному изображению.
В общем случае, построенный алгоритм будет иметь модульную структуру. Процедуры, входящие в его состав, выполняются последовательно. Каждой процедуре соответствует алгоритм, чья структура хранится в базе знаний системы.
Для построения процедуры обнаружения по описанию объекта необходимо найти в базе знаний типовой алгоритм, чья модель соответствует модели объекта. Модель алгоритма в базе знаний представляет собой структуру набора условий, налагаемых на точки изображения и характер связей между ними, а также набор параметров, которые задаются пользователем. Соответствие структуры моделей устанавливается сопоставлением условий из модели объекта и условий из модели алгоритма. После того как типовой алгоритм найден, осуществляется настройка его модели для конкретного объекта.
Для построения процедур обнаружения применяются эквивалентные преобразования моделей объектов. К таким операциям будем относить:
· перестановка предикатов в описании модели объекта;
· редукция модели на две части.
Использование перестановки предикатов в описании модели объекта позволяет получать несколько описаний (моделей) одного и того же объекта:
![]() ,
,
![]()
и т.д.
Из полученного множества моделей выделяются те, которым можно сопоставить некоторый алгоритм обнаружения, хранящийся в базе знаний.
Каждое из полученных таким образом описаний соответствует различным алгоритмам обнаружения.
В рамках операции декомпозиции модели разбиваем исходное описание на две части:
![]() и
и ![]() .
.
Структура исходной модели в
целом не может путем перестановки условий быть приведена в соответствие
структуре модели некоторого метаалгоритма, но, удаляя часть условий из описания
объекта, такое соответствие удается установить. Результатом работы полученного
алгоритма будет список объектов, удовлетворяющих «загрублённой» модели ![]() . Далее по описанию объекта
. Далее по описанию объекта ![]() строятся
процедуры обнаружения, которые анализируют объекты из полученного списка,
выбирая из них те, которые удовлетворяют также и модели
строятся
процедуры обнаружения, которые анализируют объекты из полученного списка,
выбирая из них те, которые удовлетворяют также и модели ![]() , а значит и исходной
модели Obj в целом.
, а значит и исходной
модели Obj в целом.
Для построенных процедур обнаружения при их применении для каждого конкретного тестового изображения вычисляются введённые выше оценки.
5. Базовые алгоритмы обнаружения
В рамках данной работы использовались два типа метаалгоритмов:
1. Алгоритмы обнаружения объектов, описываемых иерархическими нерекурсивными структурными моделями. В работе применён один из алгоритмов этого типа – классическое преобразование Хафа [11,12].
Классическое преобразование Хафа предназначено для выделения на изображении прямых линий, заданных параметрическими уравнениями. Оно основывается на использовании пространства параметров, в котором производится поиск прямых. Точки изображения голосуют за все возможные гипотезы (проходящие через них прямые линии), и параметры найденных прямых соответствуют локальным максимумам в пространстве параметров. Очевидно, что классическое преобразование Хафа можно использовать для нахождения любых контурных объектов, заданных в параметрическом виде.
2. Алгоритмы обнаружения объектов, описываемых иерархическими рекурсивными структурными моделями. Из данного класса был выбран алгоритм, функционирующий на основе рекурсивного перебора всех точек изображения для проверки условий из описания объекта.
6. Исходные данные
Исходными данными для системы логического вывода являются текстовое описание искомого объекта на созданном языке спецификаций, а также изображения контурных объектов (в режиме тестирования построенных процедур обнаружения).
Описание искомого объекта представляет собой параметрическую яркостно-геометрическую модель, которая, в общем случае, является рекурсивной. Объект задаётся набором условий, накладываемых на точки объекта и связи между ними.
Приведём пример использования созданного языка для задания объекта «прямая штриховая линия». Объект «штрих» определим как прямолинейный связанный отрезок. В данном примере «штрих» будем рассматривать в качестве низкоуровнего элемента описания. Предположим, что на этапе предварительной обработки на исходном изображении выполнена сегментация штрихов. Задача состоит в обнаружении множества штрихов, которые лежат на одной прямой (определяемой через значения угла наклона (phi) перпендикуляра и расстояние (ro) до начала координат), при этом расстояние (gap) между соседними элементами фиксировано.
|
dashed_line(X.LY,(DOUBLE(0,100,1))ro,(DOUBLE(0,6.28,0.15))phi,DOUBLE(0,10,1))gap):- |
|
|
|
on_line(X,ro,phi), |
|
|
distance(X,head(LY),gap), |
|
|
dashed_line(LY,ro,phi). |
|
dashed_line(X.NIL,(DOUBLE(0,100,1))ro,(DOUBLE(0,6.28,0.15))phi,DOUBLE(0,10,1))gap):- |
|
|
|
on_line(X,ro,phi). |
Где:
X.LY - список штрихов, причём X является головой списка, LY - хвостом;
DOUBLE(const1,const2,const3) - специфицирует тип переменной: const1,const2 - минимальное и максимальное значения переменной, const3 - шаг её изменения;
head(LY) - возвращает первый элемент списка LY;
on_line(X,ro,phi) - истинен, если элемент X лежит на прямой, определяемой параметрами ro, phi;
distance(X,Y,gap) - истинен, если расстояние между элементами X и Y равно значению переменной gap.
В данном описании в именах скалярных переменных используются строчные буквы, а в именах списках - прописные.
В дальнейшем для наглядности при демонстрации преобразований моделей будем использовать упрощённую запись:
|
dashed_line(X.LY,ro,phi,gap):- |
||
|
|
on_line(X,ro,phi), |
|
|
|
distance(X,head(LY),gap), |
(М1) |
|
|
dashed_line(LY,ro,phi). |
|
|
dashed_line(X.NIL,ro,phi,gap):- |
||
|
|
on_line(X,ro,phi). |
|
7. Модели алгоритмов обнаружения.
К рассмотрению были приняты следующие модели алгоритмов.
1. Модель алгоритма, реализующего классическое преобразование Хафа. Данная модель определяется тремя параметрическими условиями:
· параметрическое уравнение, связывающее координаты точек, принадлежащих искомому объекту;
· условие на точки изображения, которому должны удовлетворять все точки, принадлежащие искомому объекту;
· определение операций над свидетельствами, которые поступают от точек изображения и голосуют в пользу проходящих через них прямых линий.
2. Модель рекурсивного алгоритма. Модель определяется условиями, накладываемыми на точки объекта и связи между ними.
3. Смешанная модель. Модель соответствует алгоритму, включающему два этапа:
1. Применение процедуры классического преобразования Хафа ко всему входному изображению.
2. Применение рекурсивного алгоритма к результатам, полученным на предыдущем этапе.
Данная модель используется в случаях, когда невозможно применение одной из введённых выше «чистых» моделей.
8. Построение моделей алгоритмов.
Построение моделей осуществляется по результатам синтаксического разбора описания исходного объекта.
Рассмотрим общие принципы построения каждой из введённых выше моделей.
· В качестве условий, формирующих модель рекурсивного алгоритма, используются условия, фигурирующие в исходном описании объекта.
· Идея построения модели классического преобразования Хафа по структурному и, в общем случае, рекурсивному описанию объекта основана на выделении трёх групп предикатов, используемых в описании.
1. Предикаты, реализующие рекурсию.
2. Предикаты, накладывающие условия только на точки изображения и не связанные с точками и списками точек, которые используются в предикатах из первой группы.
3. Предикаты, связывающие аргументы предикатов из первой и второй группы.
Семантически назначением предикатов, принадлежащих первой группе, является организация просмотра всех точек изображения. Сопоставим рекурсивному просмотру всех точек последовательный просмотр в классическом преобразовании Хафа.
Предикаты из второй группы накладывают условия на отдельные точки искомого объекта, не учитывая связи между ними. Данные предикаты реализуют первые два параметрических условия в модели преобразования Хафа.
Предположим, что третье параметрическое условие в модели преобразования Хафа пользователь определяет независимо от задания объекта поиска. Очевидно, что в этом случае модель Хафа однозначно определяется по рекурсивному описанию объекта.
Из вышесказанного следует, что если третья из рассмотренных групп предикатов является пустой, то построенная модель классического преобразования Хафа описывает алгоритм поиска заданного объекта.
· Построение смешанной модели осуществляется в случае наличия в описании искомого объекта предикатов, накладывающих условия на связи между точками объекта. В этом случае производится декомпозиция исходной рекурсивной модели описания на модель классического преобразования Хафа и рекурсивную модель.
Обобщённая схема построения смешанной модели содержит два этапа.
1. На первом этапе по исходному описанию объекта происходит построение модели классического преобразования Хафа. При данных условиях полученная модель является «загрублением» исходной модели, т.к. в ней не учитываются условия, накладываемые на связи между точками (предикаты из третьей группы).
2. Целью второго этапа построения смешанной модели является создание рекурсивной модели алгоритма, выполняющего выделение искомых объектов из множества решений, полученных применением «загрублённой» модели.
Поясним рассмотренные принципы построения моделей на примере введённой выше модели «прямая штриховая линия».
Модель рекурсивного алгоритма будет построена по исходному описанию М1 без каких-либо предварительных преобразований.
Построение модели преобразования Хафа, которая бы однозначно соответствовала исходной модели, невозможно, т.к. в описании объекта присутствует предикат, принадлежащий третьей из введённых выше групп: distance(X,head(LY),gap).
Для построения смешанной модели применим к модели М1 операцию перестановки предикатов. Получим модель М1':
|
dashed_line(X.LY,ro,phi,gap):- |
||
|
|
on_line(X,ro,phi), |
|
|
|
dashed_line(LY,ro,phi), |
(М1') |
|
|
distance(X,head(LY),gap). |
|
|
dashed_line(X.NIL,ro,phi,gap):- |
||
|
|
on_line(X,ro,phi). |
|
Проведем декомпозицию модели М1'. Получим модель М1'':
|
dashed_line1(X.LY,ro,phi,gap):- |
||
|
|
on_line(X,ro,phi), |
|
|
|
dashed_line1(LY,ro,phi) |
(М1'') |
|
dashed_line1(X.NIL,ro,phi,gap):- |
||
|
|
on_line(X,ro,phi). |
|
и модель М1''':
|
dashed_line2(X.LY,ro,phi,gap):- |
||
|
|
distance(X,head(LY),gap), |
(М1''') |
|
|
dashed_line2(LY,ro,phi). |
|
|
dashed_line2(X.NIL,ro,phi,gap):- TRUE |
||
Модель М1'' является «загрублением» исходной модели М1. Ей удовлетворяет любое неупорядоченное множество штрихов, с произвольным размером промежутка между соседними штрихами. Заметим, что по описанию М1'' можно построить модель алгоритма преобразования Хафа: предикат on_line(X,ro,phi) накладывает условия на отдельные элементы (штрихи) искомого объекта, предикат dashed_line1(LY,ro,phi) определяет последовательный просмотр всех штрихов на изображении.
Модель М1''' определяет рекурсивный алгоритм выбора из множества штрихов, полученных на первом этапе, только упорядоченных наборов с заданным расстоянием между соседними элементами.
Таким образом, упорядоченная пара (М1'',M1''') определяет смешанную модель алгоритма поиска заданного объекта на изображении.
9. Применение моделей алгоритмов.
Применение построенных моделей осуществляется на целевых изображениях, которые задает пользователь. Далее приведены принципы применения каждой из введённых моделей.
· Алгоритм вычисления рекурсивной модели основывается на стандартной стратегии управления исполнением логических программ – поиск слева направо в глубину с возвратом. Для каждого текущего предиката система либо выполняет его, либо осуществляет подстановку на его место правой части предложения, реализующего данный предикат. В случае наличия нескольких реализаций одного предиката, они подставляются последовательно после окончания каждой ветви вычислений.
· Применение модели классического преобразования Хафа к конкретному изображению осуществляется в соответствии с правилами функционирования данного алгоритма.
· Смешанная модель применяется в два этапа:
1. Применение созданной модели классического преобразования Хафа. В качестве входных данных используется всё исходное изображение.
2. Применение созданной рекурсивной модели к множеству точек, удовлетворяющих модели Хафа.
10. Программная реализация.
Разработанная система логического вывода реализована на языке C++.
Входными данными для программной системы являются:
· текстовый файл, содержащий описание искомого объекта на созданном языке спецификаций;
· изображение в формате BMP для тестирования построенных моделей (не требуется на этапе построения моделей).
Выходными данными системы являются:
· обнаруженные на целевом изображении объекты после применения построенной модели алгоритма;
· статистические данные (количество операций и размер дополнительно используемой памяти), полученные при применении модели к целевому изображению.
11. Заключение.
Рассмотрим основные результаты, полученные при выполнении данной работы.
1. Разработан метод построения процедур обнаружения объекта на изображении по его структурному описанию. В основу данного метода положен механизм эквивалентного преобразования логических моделей целевого объекта. Для осуществления преобразований были введены операции над моделями:
· перестановка предикатов в описании модели объекта;
· редукция модели на две части.
Построение процедуры поиска объекта на изображении основывается на его структурном описании и на моделях известных алгоритмов.
2. Разработаны и реализованы модели для двух базовых алгоритмов обнаружения объекта на изображении, принадлежащих к различным классам алгоритмов.
· Класс алгоритмов обнаружения объектов, описываемых иерархическими нерекурсивными структурными моделями. Из данного класса был выбран алгоритм, реализующий классическое преобразование Хафа.
· Класс алгоритмов обнаружения объектов, описываемых рекурсивными структурными моделями. Из данного класса был выбран алгоритм, функционирующий на основе рекурсивного перебора всех точек изображения для проверки условий из описания объекта.
3. На основе указанных выше базовых алгоритмов была синтезирована модель производного алгоритма. На первом этапе он функционирует на основе модели классического преобразования Хафа. Результаты первого этапа являются входными данными для функционирующего на втором этапе рекурсивного алгоритма.
4. Разработана система логического вывода, реализующая метод построения процедур идентификации объекта для рассмотренных базовых алгоритмов. Входными данными для данной системы является структурное рекурсивное описание искомого объекта на пиксельном уровне. Исходная модель объекта формулируется на разработанном языке спецификаций, прототипом которого является язык логического программирования Пролог. Система осуществляет преобразование рекурсивной модели данного объекта в модель, соответствующую классическому преобразованию Хафа, или смешанную (производную) модель. В системе предусмотрен режим тестирования полученных процедур на целевых изображениях. В этом случае результатом работы системы являются:
· обнаруженный на изображении объект;
· количество операций совершённых каждой процедурой;
· размер дополнительной памяти, требуемой для функционирования каждой процедуры.
Применение разработанного метода автоматизированного конструирования процедур анализа изображений позволит существенно облегчить проведение предварительного анализа и сократить временные затраты при использовании существующих алгоритмов машинного зрения.
Авторы благодарят к.ф.-м.н. Морозова А.А. за ценные замечания и помощь, оказанную при подготовке статьи.
12. Список используемой литературы.
1. Дуда Р., Харт П. Распознавание образов и анализ сцен. Москва.: Мир, 1986.
2. Марр Д. Зрение: информационный подход к изучению представления и обработке зрительных образов. Москва.: Радио и связь, 1987.
3. Forsyth D.A., Ponce J. Computer Vision: A Modern Approach. Prentice Hall, Upper Saddle River, N.J., 2002.
4. CVonline: On-Line Compendium of Computer Vision. Editor: Robert B. Fisher, Division of Informatics, University of Edinburgh. http://www.dai.ed.ac.uk/CVonline/
5. Zheltov S.U., Sibiryakov A.V., Building Extraction at State Resesarch Institute of Aviation Systems (GosNIIAS), Third International WorkShop on Automatic Man-Made objects Extraction From Aerial and Space Images, Ascona, Switherland, June 10-16, Bulkema Publishers, 2001.
6. Batchelor B.G. Intelligent Image Processing in Prolog. Springer-Verlag, London, 1991.
7. Jones A. C., Batchelor B. G. PIP - An integrated environment for developing Prolog-based image processing applications. Practical Application Co. Ltd., Blackpool, U. K., 1996.
8. Banzhaf W., Nordin P., Keller R.E., Francone F.D. Genetic Programming - an Introduction: On the Automatic Evolution of Computer Programs and Its Applications. Dpunkt.verlag and Morgan Kaufmann Publishers, Inc. USA. 1998.
9. Teller A., Veloso M. PADO: A new learning architecture for object recognition, Symbolic visual learning. Oxford University Press, 1995.
10. Братко И. Программирование на языке Пролог для искусственного интеллекта. Москва.: Мир, 1990.
11. Illingworth J., Kittler J. A survey of the Hough transform. Computer. Vision, Graphics, and Image Processing 44. 1988.
12. Risse T. Hough Transform for line Recognition: Complexity of Evidence Accumulation and Cluster Detection. Computer Vision, Graphics, and Image Processing 46, 1989.