УДК 621.396.96
АВТОМАТИЧЕСКИЙ АНАЛИЗ РАДИОИЗОБРАЖЕНИЙ ДЛЯ СИСТЕМ РАДИОВИДЕНИЯ: МОДЕЛИРОВАНИЕ И ЧИСЛЕННЫЙ ЭКСПЕРИМЕНТ
Д. М. Ермаков, А. Ю. Зражевский, А. П. Чернушич
ИРЭ им. В.А. Котельникова РАН, Фрязинский филиал
Получена 27 июня 2013 г.
Аннотация. Проведен численный эксперимент по генерации численных моделей рассеивающих поверхностей разных типов; на основе методики адаптивного обучения выполнено программное макетирование системы автоматического распознавания типов рассеивающих поверхностей по их профилям. Анализируется эффективность полученной системы для распознавания численных моделей. Продемонстрирована возможность успешного распознавания, а также указаны причины и способы устранения отдельных возникающих ошибок.
Ключевые слова: радиовидение, радиоизображение, миллиметровый диапазон волн, численное моделирование.
Abstract: Numerical experiment was carried out on the generation of numeric models of scattering surfaces of different types; based on the adaptive learning approach a program prototyping was performed of a system for automatic recognition of the scattering surface types by their profiles. The effectiveness of the resulting system for the recognition of numerical models is analyzed. The possibility of successful recognition is demonstrated, and indicated are the sources and remedies of individual errors that occur.
Key words: radiovision, radiothermal image, millimeter wave range, numerical simulation.
Введение
Активное радиовидение в миллиметровом диапазоне рассматривается как наиболее многообещающая система для приложений в области обеспечения безопасности в местах массового скопления людей [1,2]. В активных системах радиовидения сцена подсвечивается источником излучения в рабочем диапазоне, однако для таких источников очень трудно добиться некогерентного режима работы, что приводит к проблеме спекл-зашумления, с которым надо бороться, например, методом частотной фильтрации или усреднения [3]. Однако такой подход значительно уменьшает разрешение приборов. Наблюдение за картинами образующихся спеклов в активном радиовидении позволило предположить, что существуют воспроизводимые статистические характеристики спеклов, несущие дополнительную информацию для более точной идентификации наблюдаемых объектов, чем это возможно в пассивном радиовидении или в активном радиовидении с подавленным спеклообразованием. К сожалению, не существует разработанной теории синтеза текстурных особенностей спеклообразования, поэтому оправдан эмпирический подход к этой проблеме. Такой эмпирический подход активно используется в обработке лазерных [4] и радиолокационных [5] изображений.
Для отработки и развития программно-алгоритмических средств автоматического анализа изображений с некоторыми характерными структурами спекл-шума был проведен численный эксперимент, состоящий из трех этапов. На первом этапе эксперимента выполнялось численное моделирование рассеивающих поверхностей разных типов. В результате моделирования генерировались изображения этих поверхностей и их «профили», подлежащие дальнейшему анализу. На втором этапе было выполнено программное макетирование обучаемой системы автоматического распознавания типов рассеивающих поверхностей по их профилям методом обучения с учителем. На третьем этапе программный макет построенной и обученной системы автоматического анализа радиоизображений был протестирован на данных, полученных в ходе первого этапа моделирования, для оценки качества распознавания. Была показана принципиальная возможность адаптации классических схем автоматического анализа изображений для задач радиовидения.
1. Модель радиоизображения
Поставленную задачу следует рассматривать как подготовительный этап к решению следующей задачи: автоматическому определению типов поверхностей (объектов), наблюдаемых в натурном эксперименте. В натурном эксперименте тип поверхности наиболее содержательно характеризует описание ее физико-химических свойств (мокрый снег, гравий, лист металла и т.п.), связь которых с «наблюдаемыми свойствами», такими как параметры функции распределения яркостей изображения, не всегда очевидна. Поэтому на этапе численного моделирования радиоизображения была дана возможность неформально охарактеризовать генерируемые типы изображений, т.е. отнести их к одному из нескольких различаемых классов.
Для генерации модели радиоизображения использовалась формальная модель случайно расположенных на плоскости круглых объектов (спеклов) с различными радиусами и контрастом. Статистика характеристик этих объектов задавалась перед началом генерации. Также варьировались параметры фоновой яркости, гауссового размытия и добавленного шума. Типичный результат такой генерации представлен на рис. 1.
|
Рис.1 Сгенерированная модель радиоизображения. |

Считалось, что распознающей системе доступно для обработки не все изображение, а только «профиль», т.е. набор яркостей точек выстроенных по некоторой, произвольно фиксируемой, горизонтальной линии (см. рис. 1). При этом эффективная ширина диаграммы направленности устройства радионаблюдения моделировалась гауссовым размытием исходного изображения.
На дальнейших этапах эксперимента ставилась задача: построить и программно реализовать алгоритм автоматического распознавания по заданному профилю типа исходного, «порождающего» изображения, т.е., восстановления основных характеристик изображения, заданных оператором при его генерации (фоновой яркости, плотности кругов, параметров распределений кругов по яркостям и размерам).
Таким образом, рассматривается задача автоматического соотнесения анализируемого профиля с одним из неформально определенных оператором классов изображений.
2. Обучение и автоматическое распознавание
Для решения задачи была выбрана схема обучения с учителем [6]. Оператор определяет (и описывает) некоторое число классов созданных им изображений и осуществляет обучение распознающего алгоритма, который строит оптимальное правило соотнесения заданного профиля с назначенным классом изображения. После накопления достаточного объема статистики решающий алгоритм становится способен проводить распознавание в полностью автоматическом режиме.
В описанной выше схеме алгоритм автоматического распознавания работает в особом пространстве «признаков»: величин, вычисляемых по входным данным (профилям) на основе некоторых правил. Трудность задачи состоит в том, чтобы подобрать набор признаков, который адекватно характеризовал бы связь между входными данными и классами изображений, к которым эти данные следует отнести. Как правило, чем большее число классов необходимо различать по входным данным и чем тоньше отличия между классами, тем сложнее устроено пространство признаков (за счет большего числа признаков и правил вычисления каждого из них).
Решение задачи разбили на два этапа. На первом этапе рассмотрели упрощенный вариант задачи: изображения различались только по фоновой яркости (светлые и темные) и по плотности кругов на единицу площади (высокая, средняя, низкая). Распределения кругов по размеру и яркости были жестко фиксированы. Таким образом, всего получалось шесть различаемых классов изображений. На втором этапе решался более сложный вариант задачи с меняющимися распределениями.
С методической точки зрения такое разделение задачи преследовало две цели. Во-первых, алгоритм и реализующий его программный макет были быстро созданы, проверены и отлажены на более простом варианте задачи, а затем легко адаптированы под более сложный вариант. Во-вторых, на данном примере было продемонстрировано, что если в задаче радиовидения повысить требования к детальности анализа (различению большего числа классов объектов), то это вызывает необходимость расширения числа независимых признаков, по которым должна анализироваться входная информация.
В первом варианте задачи изображения различали только по фоновой яркости и по плотности кругов при фиксированных распределениях кругов по размеру и яркости. Предварительный анализ задачи показывает, что относительное расположение кругов на изображении не должно влиять на тип изображения: фоновый тон и число кругов различной яркости и размера на единицу площади однозначно влияет только на долю площади изображения, покрытую точками той или иной яркости. Каждому классу изображений соответствует свое распределение этих долей площади разной яркости, или, иными словами, своя гистограмма яркостей точек (далее – просто гистограмма яркостей). Важно отметить, что гистограмма яркостей не содержит избыточную информацию о расположении точек различной яркости на изображении. Поскольку в качестве входных данных для алгоритма распознавания используются не сами изображения, а построенные на их основе профили, необходимо исходить из предположения, что профили несут достаточно полную информацию о порождающих изображениях, и, соответственно, что гистограммы яркостей профилей жестко связаны (в некотором смысле, схожи) с гистограммами яркостей самих изображений. Тогда на основе гистограмм яркостей профилей можно построить набор признаков, пригодных для решения сформулированной задачи распознавания.
В эксперименте это было сделано следующим образом. Весь диапазон допустимых значений яркостей (0 – 255) разбили на N равных интервалов (в ходе тестирования и отладки было выбрано N = 16):
![]() (1)
(1)
Для каждого из интервалов Ii, i=0..N-1 подсчитывали число ci точек профиля, имевших яркость в этом диапазоне. Формировали для каждого профиля j вектор Сj:
![]() (2)
(2)
Компоненты вектора Cj нормировали, получали вектор Fj:
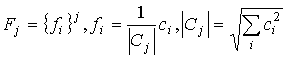 (3)
(3)
Легко видеть, что компоненты векторов Fj можно считать признаками для анализируемого профиля.
Прежде всего, поскольку все профили равной длины имеют одинаковое число точек P, то для всех таких профилей сумма компонент ci вектора Cj постоянна и равна числу P (по построению вектора Cj):
![]() (4)
(4)
Далее, поскольку компоненты вектора Fj пропорциональны компонентам вектора Cj, а длина Fj равна 1 по построению (3), то по вектору Fj можно однозначно восстановить вектор Cj, помножив компоненты fi на такой коэффициент, при котором будет выполнено условие (4). Более того, если два профиля получены для двух изображений разной длины, но одного типа, то вероятность возникновения на обоих профилях точки той или иной яркости должна быть примерно одинакова, поэтому гистограммы яркостей этих профилей, а, следовательно, и построенные для них векторы Cj будут пропорциональны друг другу. При нормировке этих векторов будет получен один и тот же вектор Fj, что удовлетворяет одному из интуитивных представлений о наборе признаков: для изображений одного типа (даже разных по размерам) признаки должны совпадать. С другой стороны, видно, что векторы Fj являются не чем иным, как огрубленными (рассчитанными для широких ячеек) и нормированными гистограммами профилей, т.е., согласно приведенным выше рассуждениям должны отражать их характерные особенности.
По определению (2, 3) векторы Fj лежат в положительном квадранте 16-мерного пространства:
![]() (5)
(5)
По условию нормировки (3) их концы располагаются на сфере единичного радиуса. Таким образом, в качестве меры отличия двух векторов признаков естественно принять угловое расстояние между ними. В теории обучения машин более распространено использование меры близости, в качестве которой в данном случае использовано скалярное произведение векторов.
Процесс обучения распознающей системы во введенном пространстве признаков заключается в наполнении обучаемой системой своих баз данных, где в формализованном виде хранятся «знания», передаваемые системе оператором. В ходе обучения осуществляется работа с двумя базами данных. Первая база данных хранит набор векторов признаков, рассчитанных по всем предъявленным ей оператором профилям вместе с идентификаторами (номерами) классов соответствующих изображений, которыми порождены эти профили. Вторая база данных содержит только «эталонные» векторы в пространстве признаков, которые «наилучшим» образом характеризуют различаемые классы изображений.
Оператор предъявляет системе очередной профиль и одновременно указывает, изображением какого типа, по его мнению, этот профиль порожден (класс изображения). Система рассчитывает по входному профилю вектор признаков Fj. Если указанный оператором класс – новый для обучаемой системы, она сразу запоминает полученный вектор признаков в качестве эталона Tk для данного класса,
![]() (6),
(6),
где k – номер нового класса, после чего переходит к анализу коллизий (см. ниже).
Если указанный класс не является новым (т.е., образцы векторов признаков для данного класса уже хранятся в системе), то система уточняет эталон класса, в данном случае, вычисляя средний вектор по всем имеющимся образцам и приводя его затем к единичной длине:
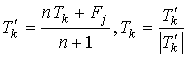 (7),
(7),
где n – число хранившихся в системе образцов профилей для данного класса перед поступлением Fj.
Выполнив над полученным профилем одну из двух описанных выше процедур и обновив свои базы данных, система проверяет их на отсутствие коллизий. Возникновение коллизий является критерием того, что оператор в ходе обучения ввел в систему ошибочную или противоречивую информацию (например, неверно сопоставив предъявленный профиль с тем или иным классом изображений). Проверка на наличие коллизий использует процедуру автоматического распознавания уже хранящихся в базе данных образцов векторов признаков. Процедура автоматического распознавания описана ниже, а результатом ее применения к данному вектору признаков является определение класса, к которому должно быть отнесено породившее его изображение. Диагностическим признаком коллизии является несовпадение класса, определенного для данного вектора признаков автоматически, и класса, назначенного для него же оператором. Источником коллизии, помимо ошибок оператора, может стать некорректная постановка задачи, т.е. попытка обучить систему различению нескольких типов изображений, принципиально не различимых в сформированном пространстве признаков. Базы данных, содержащие коллизии, не могут быть использованы системой. Коллизии должны быть устранены, например, путем удаления из системы проблемной порции входных данных.
Такая классическая схема обучения исходит из гипотезы, что в случае корректной постановки задачи и безошибочных действий оператора по мере накопления статистики набор эталонов для всех различаемых классов будет устойчиво стремиться к некоторым векторам, которые «наилучшим» образом описывают классы во введенном пространстве признаков.
Недостаточность накопленной статистики может проявляться в отдельных ошибках, которые будет совершать система в ходе автоматического распознавания новых предъявляемых ей профилей. При этом, в случае корректно поставленной задачи число ошибок должно уменьшаться в ходе обучения, в то время как при некорректно поставленной задаче число ошибок может нарастать, более того, обучение дальше некоторого предела может прекратиться из-за постоянного возникновения коллизий.
Процедура автоматического распознавания профилей обученной системой проста. Как и в случае обучения, сначала система рассчитывает по данному профилю его вектор признаков Fj. Затем, она ищет максимально похожий на него эталон Tr среди известных ей эталонов классов Tk, используя в качестве меры близости скалярное произведение:
![]() (8).
(8).
Найденный индекс r наилучшего соответствия дает номер класса, к которому система относит гипотетическое «породившее изображение», а само скалярное произведение может служить простейшей мерой достоверности распознавания в диапазоне от 0 (абсолютная неуверенность) до 1 (полная уверенность). Как сказано выше, эта процедура применяется и для проверки баз данных системы на отсутствие коллизий, при этом, однако, величина максимального скалярного произведения не учитывается.
Для обучения системы распознавания использовали в общей сложности 21 профиль, относящийся к одному из шести классов изображений: темного (0,1 от максимальной яркости), либо светлого (0,9 от максимальной яркости) фона с высокой (200 усл. ед.), средней (100 усл. ед.), либо низкой (50 усл. ед.) плотностью покрытия кругами. Распределения кругов по размерам и яркостям были жестко фиксированы.
Для проверки качества распознавания обученной системы использовали 63 профиля, построенных частично по изображениям с теми же контрольными параметрами, что определены выше, а частично – с незначительно измененными контрольными параметрами (плотностями покрытия) для проверки устойчивости распознавания. Во всех случаях распознавания система дала «разумные», интуитивно ожидаемые результаты, а в случаях строгого соответствия порождающих изображений одному из классов, на которых она была обучена, восстановленные в результате распознавания контрольные параметры точно соответствовали исходным. Результаты распознавания всех 63 профилей резюмированы в Таблице 1.
|
Таблица 1. Результаты автоматического распознавания профилей («простой случай»)
* В случае, когда порождающее изображение не относится строго к одному из шести определенных классов, в качестве класса изображения принимается класс наиболее «похожих» на него изображений по мнению оператора («экспертная оценка»); схожесть можно также понимать в смысле близости параметров. ** Значения параметров фона и плотности заполнения кругами передаются системе оператором в процессе обучения (после запоминания каждого нового класса). *** Если исходное изображение не относится строго к одному из шести определенных классов, под правильным распознаванием понимается совпадение результата распознавания с экспертной оценкой. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Анализ результатов показывает, что в рассмотренном случае система демонстрирует отличное качество распознавания даже после обучения на небольшом числе примеров (в среднем 3,5 профиля на класс). Такой результат определяется как простотой модели входных данных, так и сравнительно малым числом хорошо различимых классов. По мере усложнения модели порождения входных данных и повышения требований к детальности распознавания (что будет иметь место в натурных экспериментах) процесс обучения может стать значительно более длительным и трудоемким. Важно отметить, однако, что процесс обучения является разовой процедурой, а эффективность и скорость ее функционирования слабо зависят от указанных выше обстоятельств, а определяются, при заданном пространстве признаков, в основном качеством обучения (объемом и адекватностью накопленной статистики).
Второй вариант задачи является усложненной модификацией первого. Необходимость усложнения описанной выше модели ясна из следующего рассуждения. Предположим, оператор различает два простейших класса изображений: оба имеют одинаковый темный фон и покрыты светлыми кругами одинаковой яркости. В одном случае плотность покрытия низкая, но размер кругов большой, в другом наоборот – маленький размер кругов при высокой плотности покрытия. Варьируя эти два параметра можно добиться того, что на изображениях обоих классов будет примерно одинаковое соотношение светлых и темных точек. Следовательно, гистограммы этих изображений (и их профилей) станут одинаковыми, а сами профили – неразличимыми в рассмотренном ранее пространстве признаков. Попытка обучить систему на этих классах изображений приведет к быстрому возникновению коллизий в базах данных.
Описанная проблема – следствие нарушения одного из требований «простого случая», а именно фиксированного распределения кругов по яркостям и размерам. Ее можно преодолеть, расширив пространство признаков, т.е., дополнив уже существующий набор признаков теми, которые способны учесть описанные выше манипуляции с параметрами распределения кругов.
Новое отличие классов изображений связано с общим числом контрастных пятен, или, в терминах профилей, с числом и величиной «характерных» скачков яркости при проходе профиля. (Небольшое число скачков соответствует крупным, редко встречающимся объектам, большое число скачков – небольшим, часто встречающимся объектам). Охарактеризовать число и «величину» скачков профиля проще всего, взяв его производную. При этом, по аналогии с рассмотренным выше случаем, интерес представляет не сама производная, как функция смещения вдоль профиля, а гистограмма ее значений (в диапазоне от -127,5 до +127,5).
В итоге этого краткого анализа сделали вывод, что решение усложненного варианта задачи следует строить в расширенном (например, 32-мерном) пространстве признаков. Сама процедура построения нового пространства признаков аналогична описанной выше для простого случая, с той разницей, что ее необходимо дополнить расчетом первой производной профиля, а векторы признаков, и, соответственно, новые «эталоны» и «образцы» различаемых классов определить как набор из 32 (а не 16) элементов. Первые 16 элементов соответствовали «старым» признакам, а следующие 16 – рассчитанным по производной профиля. Алгоритмы обучения и автоматического распознавания оставили без изменений.
При переходе к усложненному варианту задачи было частично снято ограничение на функции распределения кругов по размерам и яркостям, благодаря чему стали возможны случаи возникновения профилей, не различимых во введенном ранее пространстве признаков, но относящихся к изображениям, которые интуитивно воспринимаются как разные. Возросшее число требующих различения классов изображений вызвало необходимость увеличения размерности пространства признаков (от 16 до 32).
Ниже обсужден один из выполненных в новом варианте задачи численных экспериментов. Рассматривалось два класса изображений, имеющих одинаковую фоновую яркость (0,1 от максимальной), одинаковую плотность покрытия кругами (400 усл. ед.), но разные функции распределения кругов по размеру и яркости. На изображениях класса 1 было больше кругов малого диаметра и яркости 0,64 от максимальной и меньше кругов большого диаметра и яркости 0,24 от максимальной. На изображениях класса 2, наоборот, круги малого диаметра имели яркость 0,64, а круги большого – 0,24, при этом соотношение между размерами и числом кругов подбирались таким образом, чтобы результирующие гистограммы яркостей для обоих классов изображений были одинаковы.
На основе сгенерированных изображений была построена серия профилей. Из нее 30 профилей были произвольно отобраны в качестве тестовой последовательности, на которой затем проверялось качество автоматического распознавания. Из оставшихся профилей сформировали несколько «обучающих» последовательностей разной длины: 2, 6, 10, 14 профилей. После обучения системы оператором на каждой из обучающих последовательностей тестировалось качество ее работы (число ошибок при распознавании тестовой последовательности профилей). Результаты тестирования сведены в таблицу 2.
|
Таблица 2. Результаты автоматического распознавания профилей («сложный случай»)
* Ошибкой типа 1 называли случай отнесения профиля класса «1» к классу «2»; ошибкой типа 2 – случай отнесения профиля класса «2» к классу «1». |
Из таблицы видно, что число ошибок резко сокращается (т.е., качество обучения возрастает) по мере увеличения длины обучающей последовательности. Следовательно, сформированное пространство признаков в целом оказалось адекватно поставленной задаче. Тем не менее, даже при существенном увеличении длины обучающей последовательности не удается полностью устранить ошибки распознавания. Это означает, что выбор в качестве дополнительных 16 признаков величин, рассчитываемых на основе производной профиля, не вполне удачен, т.к. их чувствительность падает при осреднении яркостей точек изображения в скользящем окне, которое имеет место при построении профиля. Для полного устранения ошибок распознавания необходимо модифицировать эти 16 признаков, либо дополнить их еще некоторым числом новых признаков. Поиск оптимального набора признаков станет одной из центральных задач при переходе к натурным экспериментам.
3. Выводы
В работе показана возможность внедрения в системы радиовидения некоторых стандартных методов классификации и распознавания: выполнено численное моделирование радиоизображений различных рассеивающих поверхностей, построен макет программного обеспечения для автоматического распознавания разных типов поверхностей, проведены эксперименты по распознаванию типов поверхностей на основе данных численного моделирования.
Макет программного обеспечения построен с учетом перспективных задач радиовидения и может быть легко модифицирован для анализа натурных данных. С точки зрения программной реализации такая модификация потребует только замены блока расчета признаков на основе анализа конкретной задачи распознавания и выбора адекватного пространства признаков. Следует подчеркнуть, что организацию оптимального в контексте рассматриваемой задачи радиовидения пространства признаков можно рассматривать не только как подготовительный шаг к формальному автоматическому анализу, но и как самостоятельный важный результат, позволяющий выделить и визуализировать основные интересующие факторы для дальнейшей экспертной оценки в условиях, когда автоматический анализ по какой-либо причине невозможен или неэффективен.
Эксперименты с созданным макетом программного обеспечения, показали, что задачи автоматического распознавания классов объектов и типов поверхностей, могут быть успешно решены в радиовидении путем внедрения в распознающие системы схемы обучения с учителем. На двух вариантах модельной задачи продемонстрирована возможность успешного распознавания, а также указаны причины и способы устранения отдельных возникающих ошибок.
Благодарности
Авторы хотят выразить свою благодарность Е.Б. Терентьеву, принявшему важное участие в программном макетировании численного эксперимента в части моделирования радиоизображений.
1. Jurgen Detlefsen, Alexander Dallinger and Simon Schelkshorn, “Approaches to Millimeter-Wave Imaging of Humans”, European Radar Conference 2004, Amsterdam, pp. 279-282
2. Leonid V. Volkov, Alexander I. Voronko, Natalie L. Volkova, Aram R. Karapetyan, “Active MMW Imagin Technique for Contraband Detection”, 33rd European Microwave conference, Munich 2003, pp. 531-534.
3. Appleby R., Wallace H.B. “Standoff Detection of Weapons and Contraband in the 100 GHz to 1 THz Region”, IEEE transactions on antennas and propagation. 55, N 11. P. 2944. (2007).
4. Франсон, М. Оптика спеклов: Пер. с фр. Текст. / М. Франсон. — М.: Мир, 1980. — 171 с.
5. Dong Y., Milne A.K., Forster B.C. Review of SAR Speckle Filters: Texture Restoration and Preservation . Geoscience and Remote Sensing Symposium, 2000. Proceedings. IGARSS 2000. IEEE 2000 International P. 633 (2000)
6. Браверман Э.М., Мучник И.Б. Структурные методы обработки эмпирических данных. М.: Наука. 1983. 464 с.